Мы уже писали о том, что в решении номер 1 StarWind iSCSI SAN для создания отказоустойчивых хранилищ VMware vSphere, есть возможность создания дедуплицированных виртуальных дисковых устройств (и вот тут), на которых могут быть размещены виртуальные машины.
Те из вас, кто следит за обновлениями StarWind, знают, что в последних версиях продукта появилась возможность репликации дедуплицированных устройств на другой узел кластера StarWind. Причем можно использовать репликацию дисковых устройств как в локальной сети, так и через WAN-сети в целях создания DR-площадки виртуальной инфраструктуры (пока экспериментально).
27-го августа выйдет StarWind iSCSI SAN 6.0, возможно, там последняя конфигурация уже будет поддерживаться полноценно. Пока ее можно тестировать и оценивать производительность и надежность.
Ну а чтобы уже сейчас приступить к развертыванию реплицируемых дедуплицированных iSCSI-хранилищ для вашей инфраструктуры VMware vSphere, компания StarWind выпустила хороший мануал по настройке этой функции "StarWind iSCSI SAN 5.9 Beta : DD devices with replication".
Ну и будете на VMworld 2012 - заходите на стенд StarWind (номер 536) - коллеги расскажут много интересного.
О версии StarWind 5.9 мы уже писали, так вот она, не перетекая в релиз, превратилась в бету StarWind iSCSI SAN 6.0, чтобы выйти уже со всеми новыми возможностями в мажорном обновлении.
Новые возможности StarWind iSCSI SAN 6.0:
Улучшенное управление HA-устройствами. Теперь можно добавить новый узел кластера StarWind к HA-устройству, удалить узел или переключиться между ними без необходимости заново пересоздавать HA Device.
HA-устройство может использовать другие типы устройств StarWind для хранения данных. Это может быть дедуплицированный диск, "тонкое" устройство IBV или устройство типа DiskBridge.
Асинхронная репликация для дедуплицированных хранилищ. Любой iSCSI target может быть использован как хранилище назначения для репликации.
Возможность загрузки бездисковых серверов по iSCSI для хранилищ StarWind. Подробно процедура настройки этой функции описана в документе "StarWind iSCSI Boot".
Улучшенное резервное копирование для виртуальных машин VMware ESX/ESXi.
Некоторые дополнительные возможности для резервного копирования виртуальных машин на Hyper-V.
Новый GUI для управления процессом резервного копирования (интегрирован в Management Console).
Упрощенный процесс подключения серверов Hyper-V и ESXi.
Скачать бета-версию StarWind iSCSI SAN 6.0 можно по этой ссылке. Более подробно о новых возможностях можно прочитать на форуме.
Таги: StarWind, iSCSI, Update, Storage, HA, VMware, vSphere, Microsoft, Hyper-V
Мы уже писали о продукте VMware vSphere Storage Appliance, который позволяет организовать отказоустойчивую инфраструктуру хранилищ на базе локальных дисков хост-серверов VMware ESXi, которые реализуют общее хранилище за счет зеркалирования томов и экспорта хранилищ хостам по протоколу NFS. Узлы ESXi с использованием VSA могут образовывать двух- или трехузловой кластер:
В случае, например, использования двухузлового кластера VSA совместно с технологией VMware Fault Tolerance, может возникнуть такая ситуация - когда Primary VM находится на хосте ESXi и использует основную копию тома с его локальных дисков. В случае сбоя этого хоста возникает двойной отказ - и виртуальной машины, которая на нем исполняется, и ее хранилища, так как оно находилось на дисках хоста. В этом случае возникает неизбежный простой ВМ до того момента, как подхватится хранилище с другого хоста и Secondary VM сможет его использовать.
В такой ситуации VMware рекомендует поступать так:
А именно: размещать хранилище защищенной FT виртуальной машины (ее виртуальные диски и файлы) на хосте, отличном от того, на котором она исполняется, т.е. на том хосте ESXi, где исполняется Secondary VM. В этом случае при любом отказе двойного сбоя не будет - всегда выживет или исполняющаяся ВМ или ее хранилище, которое подхватится Secondary VM.
В случае трехузловой конфигурации VSA можно пойти дальше: разместить Primary VM на одном узле, Secondary VM на другом, а файлы этой ВМ на третьем узле кластера VSA.
Таги: VMware, VSA, Fault Tolerance, FT, HA, Storage
Недавно мы уже писали о том, как работает технология балансировки нагрузки на хранилища VMware Storage DRS (там же и про Profile Driven Storage). Сегодня мы посмотрим на то, как эта технология работает совместно с различными фичами дисковых массиов, а также функциями самой VMware vSphere и других продуктов VMware.
Для начала приведем простую таблицу, из которой понятно, что поддерживается, а что нет, совместно с SDRS:
Возможность
Поддерживается или нет
Рекомендации VMware по режиму работы SDRS
Снапшоты на уровне массива (array-based snapshots)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Дедупликация на уровне массива (array-based deduplication)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Использование "тонких" дисков на уровне массива (array-based thin provisioning)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Использование функций автоматического ярусного хранения (array-based auto-tiering)
Поддерживается
Ручное применение рекомендаций (Manual Mode), только для распределения по заполненности хранилищ (auto-tiering по распределению нагрузки сам решит, что делать)
Репликация на уровне массива (array-based replication)
Автоматическое применение рекомендаций (Fully Automated Mode)
Технология репликации на уровне хоста (VMware vSphere Replication)
Не поддерживается
-----
Снапшоты виртуальных машин (VMware vSphere Snapshots)
Поддерживается
Автоматическое применение рекомендаций (Fully Automated Mode)
Использование "тонких" дисков на уровне виртуальных хранилищ (VMware vSphere Thin Provisioning)
Поддерживается
Автоматическое применение рекомендаций (Fully Automated Mode)
Технология связанных клонов (VMware vSphere Linked Clones)
Не поддерживается
-----
"Растянутый" кластер (VMware vSphere Storage Metro Cluster)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Хосты с версией ПО, младше чем vSphere 5.0
Не поддерживается
-----
Использование совместно с продуктом VMware vSphere Site Recovery Manager
Не поддерживается
-----
Использование совместно с продуктом VMware vCloud Director
Не поддерживается
-----
Комментарии к таблице:
Снапшоты на уровне массива - они никак не влияют на работу механизма SDRS, однако рекомендуется оставить его в ручном режиме, чтобы избежать возможных проблем при одновременном создании снапшота и перемещении виртуальных дисков.
Дедупликация на уровне массива - полностью совместима со механизмом SDRS, однако рекомендуется ручной режим, так как, с точки зрения дедупликации, наиболее эффективно сначала применить рекомендации по миграции виртуальных дисков, а потом уже использовать дедупликацию (для большинства сценариев).
Использование array-based auto-tiering - очевидно, что функции анализа производительности в дисковом массиве и перемещения данных по ярусам с различными характеристиками могут вступить вступить в конфликт с алгоритмами определения нагрузки в SDRS и перемещения vmdk-дисков по хранилищам на логическом уровне. Сам Storage DRS вступает в действие после 16 часов анализа нагрузки и генерирует рекомендации каждые 8 часов, в дисковом же массиве механизм перераспределения блоков по ярусам может работать по-разному: от real-time процесса в High-end массивах, до распределения каждые 24 часа в недорогих массивах. Понятно, что массиву лучше знать, какие блоки куда перемещать с точки зрения производительности физических устройств, поэтому для SDRS рекомендуется оставить выравнивание хранилищ только по заполненности томов VMFS, с отключенной I/O Metric.
Репликация на уровне массива - полностью поддерживается со стороны SDRS, однако, в зависимости от использования метода репликации, во время применения рекомендаций SDRS виртуальные машины могут остаться в незащищенном состоянии. Поэтому рекомендуется применять эти рекомендации SDRS во время запланированного окна обслуживания хранилищ.
VMware vSphere Storage Metro Cluster - здесь нужно избегать ситуации, когда виртуальный диск vmdk машины может уехать на другой сайт по отношению к хосту ESXi, который ее исполняет (когда используется общий Datastore Cluster хранилищ). Поэтому, а еще и потому, что распределенные кластеры могут строиться на базе технологий синхронной репликации хранилищ (см. предыдущий пункт), нужно использовать ручное применение рекомендаций SDRS.
Поддержка VMware vSphere Site Recovery Manager - на данный момент SDRS не обнаруживает Datastore Groups в SRM, а SRM не отслеживает миграции SDRS по хранилищам. Соответственно, при миграции ВМ на другое хранилище не обновляются protection groups в SRM, как следствие - виртуальные машины оказываются незащищенными. Поэтому совместное использование этих продуктов не поддерживается со стороны VMware.
Поддержка томов RDM - SDRS полностью поддерживает тома RDM, однако эта поддержка совершенно ничего не дает, так как в миграциях может участвовать только vmdk pointer, то есть прокси-файл виртуального диска, который занимает мало места (нет смысла балансировать по заполненности) и не генерирует никаких I/O на хранилище, где он лежит (нет смысла балансировать по I/O). Соответственно понадобиться эта поддержка может лишь на время перевода Datastore, где лежит этот файл-указатель, в режим обслуживания.
Поддержка VMware vSphere Replication - SDRS не поддерживается в комбинации с хостовой репликацией vSphere. Это потому, что файлы *.psf, используемые для нужд репликации, не поддерживаются, а даже удаляются при миграции ВМ на другое хранилище. Вследствие этого, механизм репликации для смигрированной машины считает, что она нуждается в полной синхронизации, что вызывает ситуацию, когда репликация будет отложена, а значит существенно ухудшатся показатели RTO/RPO. Поэтому (пока) совместное использование этих функций не поддерживается.
Поддержка VMware vSphere Snapshots - SDRS полностью поддерживает спапшоты виртуальных машин. При этом, по умолчанию, все снапшоты и виртуальные диски машины при применении рекомендаций перемещаются на другое хранилище полностью (см. левую часть картинки). Если же для дисков ВМ настроено anti-affinity rule, то они разъезжаются по разным хранилищам, однако снапшоты едут вместе со своим родительским диском (см. правую часть картинки).
Использование тонких дисков VMware vSphere - полностью поддерживается SDRS, при этом учитывается реально потребляемое дисковое пространство, а не заданный в конфигурации ВМ объем виртуального диска. Также SDRS учитывает и темпы роста тонкого виртуального диска - если он в течение последующих 30 часов может заполнить хранилище до порогового значения, то такая рекомендация показана и применена не будет.
Технология Linked Clones - не поддерживается со стороны SDRS, так как этот механизм не отслеживает взаимосвязи между дисками родительской и дочерних машин, а при их перемещении между хранилищами - они будут разорваны. Это же значит, что SDRS не поддерживается совместно с продуктом VMware View.
Использование с VMware vCloud Director - пока не поддерживается из-за проблем с размещением объектов vApp в кластере хранилищ.
Хосты с версией ПО, младше чем vSphere 5.0 - если один из таких хостов поключен к тому VMFS, то для него SDRS работать не будет. Причина очевидна - хосты до ESXi 5.0 не знали о том, что будет такая функция как SDRS.
Продолжаем вас знакомить с продуктом номер 1 StarWind iSCSI SAN, который удобно и просто использовать для создания отказоустойчивых хранилищ виртуальных машин VMware vSphere, Microsoft Hyper-V и Citrix XenServer. Так уж получилось, что мы рассказывали об использовании этого продукта на платформах VMware и Microsoft, а вот для XenServer от Citrix почти ничего не писали.
На эту тему можно порекомендовать несколько статей от sysadminlab.net, где на примере вот такой простецкой инсталляции:
рассматриваются основные аспекты применения продукта для создания iSCSI-хранилищ под виртуальные машины:
Как знают многие администраторы, в новой версии операционной системы Windows Server 2012 появилась возможность использования технологии Scale-Out File Servers (SOFS) для создания кластеров SMBv3.0-хранилищ типа active/active, предоставляющих надежное и отказоустойчивое файловое хранилище различным приложениям. В частности, SOFS может быть использовано для создания общего хранилища виртуальных машин серверов Microsoft Hyper-V на базе кластерной системы CSV (Cluster Shared Volumes):
Как видно из картинки, для организации инфраструктуры SOFS нам потребуется общее хранилище, построенное на базе Fibre Channel / iSCSI / SAS, что требует дополнительных затрат на оборудование, его настройку и обслуживание.
Компания StarWind предлагает организовать общее хранилище для SOFS на базе программного решения StarWind iSCSI SAN, которое позволяет организовывать кластеры отказоустойчивых хранилищ, предоставляющих общее хранилище для виртуальных машин VMware vSphere и Microsoft Hyper-V. StarWind предлагает использовать следующую схему для размещения виртуальных машин на SOFS:
О том, как работает такая инфраструктура, и как настроить ее, читайте в новых документах компании StarWind:
Как оказалось у нас на сайте нет инструкции по подключению локальных дисков сервера VMware ESXi в качестве RDM-дисков для виртуальных машин. Восполняем этот пробел. Как известно, если вы попытаетесь добавить локальный диск сервере ESXi в качестве RDM-тома для ВМ, вы там его не увидите:
Связано это с тем, что VMware не хочет заморачиваться с поддержкой дисков различных производителей, где будут размещены производственные виртуальные машины. Поэтому нам нужно создать маппинг-файл VMDK на локальное дисковое устройство, который уже как диск (pRDM или vRDM) подключить к виртуальной машине.
Для начала найдем имя устройства локального SATA-диска в списке устройств ESXi. Для этого перейдем в соответствующую директорию командой:
# cd /dev/disks
И просмотрим имеющиеся диски:
# ls -l
Нас интересуют те диски, что выделены красным, где вам необходимо найти свой и скопировать его имя, вроде t10.ATA___....__WD2DWCAVU0477582.
Далее переходим в папку с виртуальной машиной, которой мы хотим подцепить диск, например:
# cd /vmfs/volumes/datastore1/<vm name>
И создаем там маппинг VMDK-диск для создания RDM-тома, при этом можно выбрать один из режимов совместимости:
После того, как vmdk mapping file создан, можно цеплять этот диск к виртуальной машине через Add Virtual Disk (лучше использовать для него отдельный SCSI Controller):
Второй способ, который работает не для всех дисков - это отключение фильтра на RDM-диски (это можно сделать и на сервере VMware vCenter). Для этого в vSphere Client для хоста ESXi нужно пойти сюда:
Однако, повторимся, этот метод (в отличие от первого) работает не всегда. Ну и учитывайте, что подобная конфигурация не поддерживается со стороны VMware, хотя и работает.
Мы уже писали о том, что такое и как работает технология VMware vStorage API for Array Integration (VAAI) (а также немного тут), которая позволяет передать операции по работе с хранилищами, которые выполняет компонент Data Mover в VMkernel, на сторону дискового массива. Это существенно улучшает показатели производительности различных операций (клонирования и развертывания ВМ, использования блокировок) за счет того, что они выполняются самим массивом, без задействования сервера VMware ESXi:
Если ваш массив не поддерживает примитивы VAAI, то чтобы склонировать виртуальный диск VMDK размером 64 ГБ, компонент Data Mover реализует эту операцию следующим образом:
Разделяет диск 64 ГБ на малые порции размером в 32 МБ.
Эту порцию 32 МБ Data Mover разделяет еще на маленькие операции ввода-вывода (I/O) размером в 64 КБ, которые идут в 32 параллельных потока одновремнно.
Соответственно, чтобы передать 32 МБ, Data Mover выполняет 512 операций ввода вывода (I/Os) по 64 КБ.
Если же массив поддерживает примитив XCOPY (он же Hardware Offloaded Copy и SAN Data Copy Offloading), то для передачи тех же 32 МБ будут использованы I/O размером в 4 МБ, а таких I/O будет, соответственно, всего 8 штук - разница очевидна.
Интересно, как работает VAAI с точки зрения ошибок при передаче данных: например, мы делаем клонирование ВМ на массиве с поддержкой VAAI, и вдруг возникает какая-то ошибка. В этом случае VMkernel Data Mover подхватывает операцию клонирования с того места, где VAAI вызвал ошибку, и производит "доклонирование" виртуальной машины. Далее ESXi периодически будет пробовать снова использовать VAAI на случай, если это была кратковременная ошибка массива.
При этом проверки в разных версиях ESXi будут производиться по-разному:
Для ESX/ESXi 4.1 проверка будет производиться каждые 512 ГБ передаваемых данных. Посмотреть этот параметр можно следующей командой:
# esxcfg-advcfg -g /DataMover/HardwareAcceleratedMoveFrequency Value of HardwareAcceleratedMoveFrequency is 16384
Это значение частоты 16384 нужно умножить на порцию 32 МБ и мы получим 512 ГБ. Чтобы поменять эту частоту, можно использовать команду:
Для ESXi 5.0 и выше все проще - проверка производится каждые 5 минут.
Помимо описанных в нашей статье примитивов Full Copy, Zero Block и ATS, начиная с версии ESXi 5.0, поддерживаются еще 2 примитива:
Thin Provisioning - механизм сообщения хостом ESXi дисковому массиву о том, что виртуальная машина или ее файлы с Thin LUN были удалены или перемещены (в силу разных причин - Storage vMotion, консолидация снапшотов и так далее), поэтому массив может забрать это дисковое пространство себе назад.
С точки зрения дисковых массивов, работающих на NFS (прежде всего, NetApp) в ESXi 5.0 также появилась поддержка примитивов VAAI:
Full File Clone – аналог функций Full Copy для VAAI на блочных хранилищах, предназначен для клонирования файлов виртуальных дисков VMDK.
Native Snapshot Support – передача на сторону массива функций создания снапшота ВМ.
Extended Statistics – включает возможность просмотра информации об использовании дискового пространства на NAS-хранилище, что полезно для Thin Provisioning.
Reserve Space – включает возможность создания виртуальных дисков типа "thick" (фиксированного размера) на NAS-хранилищах (ранее поддерживались только Thin-диски).
Функции VAAI включены по умолчанию и будут использованы тогда, когда станут доступны (например, при обновлении Firmware дискового массива, которое поддерживает VAAI).
Таги: VMware, vSphere, VAAI, Storage, ESXi, Enterprise, SAN
Если речь идет о виртуальных машинах на сервере VMware ESXi, работающих с дисковым массивом, можно выделить 5 видов очередей:
GQLEN (Guest Queue) - этот вид очередей включает в себя различные очереди, существующие на уровне гостевой ОС. К нему можно отнести очереди конкретного приложения, очереди драйверов дисковых устройств в гостевой ОС и т.п.
WQLEN (World Queue/ Per VM Queue) - это очередь, существующая для экземпляра виртуальной машины (с соответствующим World ID), которая ограничивает единовременное число операций ввода-вывода (IOs), передаваемое ей.
AQLEN (Adapter Queue) - очередь, ограничивающая одновременное количество обрабатываемых на одном HBA-адаптере хоста ESXi команд ввода вывода.
DQLEN (Device Queue / Per LUN Queue) - это очередь, ограничивающая максимальное количество операций ввода-вывода от хоста ESXi к одному LUN (Datastore).
Эти очереди можно выстроить в иерархию, которая отражает, на каком уровне они вступают в действие:
Очереди GQLEN бывают разные и не относятся к стеку виртуализации VMware ESXi, поэтому мы рассматривать их не будем. Очереди SQLEN мы уже частично касались тут и тут. Если до SP дискового массива со стороны сервера ESX / ESXi используется один активный путь, то глубина очереди целевого порта массива (SQLEN) должна удовлетворять следующему соотношению:
SQLEN>= Q*L
где Q - это глубина очереди на HBA-адаптере, а L - число LUN, обслуживаемых SP системы хранения. Если у нас несколько активных путей к одному SP правую часть неравенства надо еще домножить на P - число путей.
Соответственно, в виртуальной инфраструктуре VMware vSphere у нас несколько хостов имеют доступ к одному LUN через его SP и получается следующее соотношение:
SQLEN>= ESX1 (Q*L*P) + ESX2 (Q*L*P)+ и т.д.
Теперь рассмотрим 3 оставшиеся типа очередей, которые имеют непосредственное отношение к хосту VMware ESXi:
Как мы видим из картинки - очереди на различных уровнях ограничивают число I/O, которые могут быть одновременно обработаны на различных сущностях:
Длина очереди WQLEN по умолчанию ограничена значением 32, что не позволяет виртуальной машине выполнять более 32-х I/O одновременно.
Длина очереди AQLEN - ограничена значением 1024, чтобы собирать в себя I/O от всех виртуальных машин хоста.
Длина очереди DQLEN - ограничена значением 30 или 32, что не позволяет "выедать" одному хосту ESXi с одного хранилища (LUN) более 30-ти или 32-х операций ввода-вывода
Зачем вообще нужны очереди? Очень просто - очередь это естественный способ ограничить использование общего ресурса. То есть одна виртуальная машина не заполонит своими командами ввода-вывода весь HBA-адаптер, а один хост ESXi не съест всю производительность у одного Datastore (LUN), так как ограничен всего 32-мя I/O к нему.
Мы уже писали о функционале Storage I/O Control (SIOC), который позволяет регулировать последний тип очереди, а именно DQLEN, что позволяет корректно распределить нагрузку на СХД между сервисами в виртуальных машинах в соответствии с их параметрами shares (эта функциональность есть только в издании vSphere Enterprise Plus). Механизм Storage IO Control для хостов VMware ESX включается при превышении порога latency для тома VMFS, определяемого пользователем. Однако, стоит помнить, что механизм SIOC действует лишь в пределах максимально определенного значения очереди, то есть по умолчанию не может выйти за пределы 32 IO на LUN от одного хоста.
Для большинства случаев этого достаточно, однако иногда требуется изменить обозначенные выше длины очередей, чтобы удовлетворить требования задач в ВМ, которые генерируют большую нагрузку на подсистему ввода-вывода. Делается это следующими способами:
1. Настройка длины очереди WQLEN.
Значение по умолчанию - 32. Его задание описано в статье KB 1268. В Advanced Settings хоста ESXi нужно определить следующий параметр:
Disk.SchedNumReqOutstanding (DSNRO)
Он глобально определяет, сколько операций ввода-вывода (IOs) может максимально выдать одна виртуальная машина на LUN одновременно. В то же время, он задает это максимальное значение в IOs для всех виртуальных машин на этот LUN от хоста ESXi (это глобальная для него настройка). То есть, если задано значение 32, то все машины могут одновременно выжать 32 IOs, это подтверждается в случае, где 3 машины генерируют по 32 одновременных IO к одному LUN, а реально к LUN идут все те же 32, а не 3*32.
2. Настройка длины очереди AQLEN.
Как правило, этот параметр менять не требуется, потому что дефолтного значения 1024 хватает практически для всех ситуаций. Где его менять, я не знаю, поэтому если знаете вы - можете написать об этом в комментариях.
3. Настройка длины очереди DQLEN.
Настройка этого параметра описана в KB 1267 (мы тоже про это писали) - она зависит от модели и драйвера HBA-адаптера (в KB информация актуальна на июнь 2010 года). Она взаимосвязана с настройкой Disk.SchedNumReqOutstanding и, согласно рекомендациям VMware, должна быть эквивалентна ей. Если эти значения различаются, то когда несколько ВМ используют с хоста ESXi один LUN - актуальной длиной очереди считается минимальное из этих значений.
Для отслеживания текущих значений очередей можно использовать утилиту esxtop, как описано в KB 1027901.
Как мы уже писали недавно, в VMware vSphere есть политика путей, называемая Fixed path with Array Preference (в интерфейсе vSphere Client 4.1 она называется VMW_PSP_FIXED_AP). По умолчанию она выбирается для дисковых массивов, которые поддерживают ALUA. Эта политика опрашивает дисковый массив (A-A или A-P), позволяя ему самому определить, какие пути использовать как preferred path, если это не указано пользователем...
Таги: StarWind, HA, iSCSI, Storage, Update, VMware, vSphere, SAN
Некоторое время назад мы уже писали о возможности конвертации RDM-томов, работающих в режиме виртуальной и физической совместимости, в формат VMDK. Сегодня мы поговорим об обратном преобразовании: из формата VMDK в формат RDM (physical RDM или virtual RDM).
Для начала опробуйте все описанное ниже на тестовой виртуальной машине, а потом уже приступайте к продуктивной. Перед началом конвертации необходимо остановить ВМ, а также сделать remove виртуального диска из списка устройств виртуальной машины. Определите, какой режим совместимости диска RDM вам необходим (pRDM или vRDM), прочитав нашу статью "Типы виртуальных дисков vmdk виртуальных машин на VMware vSphere".
Создайте новый LUN на дисковом массиве, где будет размещаться RDM-том, и сделайте Rescan на хосте ESXi, чтобы увидеть добавленный девайс в vSphere Client:
Обратите внимание на Runtime Name (в данном случае vmhba37:C0:T1:L0) и на идентификатор в скобках (naa.6000eb....итакдалее) - этот идентификатор нам и нужен. Словить его можно, выполнив следующую команду (подробнее об идентификации дисков тут):
# esxcfg-mpath -L
В результатах вывода по Runtime Name можно узнать идентификатор. Вывод будет примерно таким:
vmhba33:C0:T0:L0 state:active naa.6090a038f0cd6e5165a344460000909b vmhba33 0 0 0 NMP active san iqn.1998-01.com.vmware:bs-tse-i137-35c1bf18 00023d000001,iqn.2001-05.com.equallogic:0-8a0906-516ecdf03-9b9000004644a365-bs-lab-vc40,t,1
Соответственно, второе выделенное жирным - идентификатор, его копируем.
Далее выполняем следующую команду для конвертации диска в Virtual RDM:
Далее выберите виртуальную машину в vSphere Client и сделайте Add Disk, где в мастере укажите тип диска RDM и следуйте по шагам мастера для добавления диска. После этого проверьте, что LUN больше не показывается при выборе Add Storage для ESXi в vSphere Client. Запустите виртуальную машину и, если необходимо, в гостевой ОС в оснастке Disk Management сделайте этот диск Online.
Наш с вами коллега, Анатолий Вильчинский, проводит в ближайшие дни 2 интересных вебинара по продукту номер 1 для создания отказоустойчивых хранилищ под виртуализацию - StarWind iSCSI SAN.
Если у вас в виртуальной инфраструктуре большой набор хранилищ, хостов VMware ESXi и виртуальных машин, то легко не заметить один интересный момент - бесполезные vswp-файлы для виртуальных машин, размещенные в папке с ВМ. Выглядят они как <что-то там>.vswp.<номер чего-то там>:
Как видно из картинки, файлы эти не маленькие - размер vswp равен объему памяти, сконфигурированной для виртуальной машины (vRAM) без Reservation для RAM (если есть reservation, то размер vswp = vRAM - Reservation). Так вот эти файлы с номерами - это ненужный мусор. Образуются они тогда, когда хост ESXi падает в PSOD с запущенными виртуальными машинами.
Эти файлы, понятно дело, надо удалить. Для этого удобнее всего использовать PowerCLI:
dir vmstores:\ -Recurse -Include *.vswp.* | Select Name,Folderpath
На сайте проекта VMware Labs появилась новая интересная утилита Guest Reclaim, позволяющая уменьшить размер "тонкого" (thin provisioned) диска виртуальной машины из гостевой ОС Windows, истребовав нулевые блоки. Напомним, что когда тонкий диск виртуальной машины растет по мере наполнения данными, а потом вы эти данные в самой гостевой системе удаляете, его размер не уменьшается.
Один из способов уменьшить диск машины в VMware vSphere - это использовать утилиту sdelete для очистки блоко и перемещение виртуальной машины на другое хранилище средствами Storage vMotion. Однако, если вы прочтете нашу статью про datamover'ы при Storage vMotion и вспомните, что VMware vSphere 5 использует унифицированные блоки размером 1 МБ для всех хранилищ, то поймете, что этот способ больше не работает, поскольку в датамувере fs3dm не реализована процедура вычищения блоков целевого виртуального диска.
Есть конечно способ отключить fs3dm и, все-таки, уменьшить виртуальный диск машины на ESXi, однако это не очень удобная процедура. Поэтому сотрудники VMware и сделали удобную консольную утилитку Guest Reclaim, которая позволяет уменьшить диск с файловой системой NTFS.
Поддерживаются следующие гостевые ОС:
Windows XP
Windows Vista
Windows 7
Windows Server 2003
Windows Server 2008
Запускать утилиту нужно из гостевой ОС, в которой есть диски, являющиеся тонкими. Чтобы просмотреть список тонких дисков используйте команду:
GuestReclaim.exe -list
Если ничего не найдено - значит первые 16 дисков не являются тонкими или у вас ESXi 5.0 и ниже (читайте дальше). VMware предлагает приступать к уменьшению диска, когда у вас разница между размером VMDK и файлами гостевой ОС хотя бы 1 ГБ, при этом для работы самой утилиты может потребоваться дополнительно 16-100 МБ свободного места. Также перед началом использования утилиты рекомендуется запустить дефрагментацию диска, на которую тоже может потребоваться свободное место (будет расти сам VMDK-файл).
Команда, чтобы уменьшить тонкий VMDK-диск за счет удаления нулевых блоков, выполняемая из гостевой ОС:
guestReclaim.exe --volumefreespace D:\
Еще одно дополнение - утилиту можно использовать и для RDM-дисков.
А теперь главное - утилита работает только в случае, если hypervisor emulation layer представляет гостевой ОС диски как тонкие. В VMware ESXi 5.0, где Virtual Hardware восьмой версии, такой возможности нет, а вот в ESXi 5.1, где уже девятая версия виртуального железа - такая возможность уже есть. Соответственно, использовать утилиту вы можете только, начиная с VMware vSphere 5.1 (бета сейчас уже у всех есть), а пока можно использовать ее только для RDM-дисков.
Из ограничений утилиты Guest Reclaim:
Не работает со связанными клонами (Linked Clones)
Не работает с дисками, имеющими снапшоты
Не работает под Linux
Из дополнительных возможностей:
Поддержка томов Simple FAT/NTFS
Поддержка flat partitions и flat disks для истребования пространства
Работа в виртуальных и физических машинах
FAQ по работе с утилитой доступен по этой ссылке. Скачать утилиту можно тут.
На сайте Фрэнка Деннемана появилась отличная статья про механизмы "горячей" миграции хранилищ (Storage vMotion) и "горячей" миграции виртуальных машин (vMotion) в контексте их использования для одного хранилища (Datastore) или хоста ESXi в VMware vSphere. Мы просто не можем не перевести ее, так как она представляет большой интерес для понимания работы этих механизмов.
Начнем со Storage vMotion. Данная операция, очевидно, требует большой нагрузки как на хранилище, откуда и куда, переносятся виртуальные машины, так и на сам хост-сервер VMware ESXi. Особенно актуально это, когда хост или хранилище переходят в Maintenance Mode, и виртуальные машины массово начинают миграцию. В случае со Storage vMotion это создает колоссальную нагрузку на хранилище по вводу-выводу.
Для понимания затрат ресурсов на эти процессы Фрэнк вводит понятие "цены" (cost) начинающейся операции, которая не может превосходить количество доступных слотов на хосте или хранилище, выделенных под них. Наглядно это можно представить так:
Resource Max Cost - это максимальный объем в неких единицах (назовем их слотами), который находится в рамках пула доступных ресурсов для операции Storage vMotion. Для хоста ESXi емкость такого пула составляет 8 слотов, а цена операции Storage vMotion - 4 слота. Таким образом, на одном хосте ESXi могут одновременно выполняться не более 2-х операций Storage vMotion. Если выполняется одна операция - то занято 4 слота и 4 слота свободно (как для исходного, так и для целевого хранилища).
С хранилищем точно такая же система - но у него 128 слотов. Одна операция Storage vMotion для Datastore потребляет 16 слотов. Таким образом, на одном хранилище может выполняться 8 (128 / 16) одновременных операций Storage vMotion. Их могут инициировать, например, 4 хоста (по 2 операции максимально каждый). То есть, мы получаем следующую схему:
Все просто и понятно. Отметим здесь, что операция vMotion тоже потребляет ресурсы с Datastore - но всего 1 слот. Таким образом, на одном Datastore могут, например, выполняться 7 одновременных миграций Storage vMotion (7 * 16 = 112 слотов) и еще 16 миграций vMotion (112+16 = 128), задействующих ВМ этого Datastore.
Если вы не хотите, чтобы при переводе Datastore в Maintenance Mode на нем возникало сразу 8 одновременных миграций Storage vMotion и, как следствие, большой нагрузки, вы можете уменьшить пул слотов для хранилищ (для всех, а не для какого-то конкретно). Для этого нужно отредактировать конфигурационный файл vpxd.cfg на сервере VMware vCenter, который находится в папке:
Вбив значение 112, вы уменьшите максимальное число одновременных миграций Storage vMotion на Datastore до 7. На хосте ESXi менять размер пула слотов для Storage vMotion не рекомендуется (хотя такие секции можно добавить - это пробовали энтузиасты).
Про стоимость миграций vMotion для хостов ESX / ESXi 4.1 мы уже писали вот тут. На эту тему есть также статья KB 2001417. С тех пор в vMotion много чего изменилось, поэтому подтвердить актуальность для vSphere 5 пока не могу. Буду признателен, если вы напишете об этом в комментариях.
Как мы уже писали в одной из статей, в VMware vSphere 5 при работе виртуальных машин с хранилищами могут возникать 2 похожих по признакам ситуации:
APD (All Paths Down) - когда хост-сервер ESXi не может получить доступа к устройству ни по одному из путей, а также устройство не дает кодов ответа на SCSI-команды. При этом хост не знает, в течение какого времени будет сохраняться такая ситуация. Типичный пример - отказ FC-коммутаторов в фабрике или выход из строя устройства хранения. В этом случае хост ESXi будет периодически пытаться обратиться к устройству (команды чтения параметров диска) через демон hostd и восстановить пути. В этом случае демон hostd будет постоянно блокироваться, что будет негативно влиять на производительность. Этот статус считается временным, так как устройство хранения или фабрика могут снова начать работать, и работа с устройством возобновится.
В логе /var/log/vmkernel.log ситуация APD выглядит подобным образом:
2011-07-30T14:47:41.187Z cpu1:2049)WARNING: NMP: nmp_IssueCommandToDevice:2954:I/O could not be issued to device "naa.60a98000572d54724a34642d71325763" due to Not found
2011-07-30T14:47:41.187Z cpu1:2049)WARNING: NMP: nmp_DeviceRetryCommand:133:Device "naa.60a98000572d54724a34642d71325763": awaiting fast path state update for failover with I/O blocked. No prior reservation exists on the device.
2011-07-30T14:47:41.187Z cpu1:2049)WARNING: NMP: nmp_DeviceStartLoop:721:NMP Device "naa.60a98000572d54724a34642d71325763" is blocked. Not starting I/O from device.
2011-07-30T14:47:41.361Z cpu1:2642)WARNING: NMP: nmpDeviceAttemptFailover:599:Retry world failover device "naa.60a98000572d54724a34642d71325763" - issuing command 0x4124007ba7c0
2011-07-30T14:47:41.361Z cpu1:2642)WARNING: NMP: nmpDeviceAttemptFailover:658:Retry world failover device "naa.60a98000572d54724a34642d71325763" - failed to issue command due to Not found (APD), try again...
2011-07-30T14:47:41.361Z cpu1:2642)WARNING: NMP: nmpDeviceAttemptFailover:708:Logical device "naa.60a98000572d54724a34642d71325763": awaiting fast path state update...
2011-07-30T14:47:42.361Z cpu0:2642)WARNING: NMP: nmpDeviceAttemptFailover:599:Retry world failover device "naa.60a98000572d54724a34642d71325763" - issuing command 0x4124007ba7c0
2011-07-30T14:47:42.361Z cpu0:2642)WARNING: NMP: nmpDeviceAttemptFailover:658:Retry world failover device "naa.60a98000572d54724a34642d71325763" - failed to issue command due to Not found (APD), try again...
2011-07-30T14:47:42.361Z cpu0:2642)WARNING: NMP: nmpDeviceAttemptFailover:708:Logical device "naa.60a98000572d54724a34642d71325763": awaiting fast path state update...
Ключевые слова здесь: retry, awaiting. Когда вы перезапустите management agents, то получите такую вот ошибку:
Not all VMFS volumes were updated; the error encountered was 'No connection'.
Errors:
Rescan complete, however some dead paths were not removed because they were in use by the system. Please use the 'storage core device world list' command to see the VMkernel worlds still using these paths.
Error while scanning interfaces, unable to continue. Error was Not all VMFS volumes were updated; the error encountered was 'No connection'.
В этом случае надо искать проблему в фабрике SAN или на массиве.
PDL (Permanent Device Loss) - когда хост-серверу ESXi удается понять, что устройство не только недоступно по всем имеющимся путям, но и удалено совсем, либо сломалось. Определяется это, в частности, по коду ответа для SCSI-команд, например, вот такому: 5h / ASC=25h / ASCQ=0 (ILLEGAL REQUEST / LOGICAL UNIT NOT SUPPORTED) - то есть такого устройства на массиве больше нет (понятно, что в случае APD по причине свича мы такого ответа не получим). Этот статус считается постоянным, так как массив ответил, что устройства больше нет.
А вообще есть вот такая табличка для SCSI sense codes, которые вызывают PDL:
В случае статуса PDL гипервизор в ответ на запрос I/O от виртуальной машины выдает ответ VMK_PERM_DEV_LOSS и не блокирует демон hostd, что, соответственно, не влияет на производительность. Отметим, что как в случае APD, так и в случае PDL, виртуальная машина не знает, что там произошло с хранилищем, и продолжает пытаться выполнять команды ввода-вывода.
Такое разделение статусов в vSphere 5 позволило решить множество проблем, например, в случае PDL хост-серверу больше не нужно постоянно пытаться восстановить пути, а пользователь может удалить сломавшееся устройство с помощью операций detach и unmount в интерфейсе vSphere Client (в случае так называемого "Unplanned PDL"):
В логе /var/log/vmkernel.log ситуация PDL (в случае Unplanned PDL) выглядит подобным образом:
2011-08-09T10:43:26.857Z cpu2:853571)VMW_SATP_ALUA: satp_alua_issueCommandOnPath:661: Path "vmhba3:C0:T0:L0" (PERM LOSS) command 0xa3 failed with status Device is permanently unavailable. H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0.
2011-08-09T10:43:26.857Z cpu2:853571)VMW_SATP_ALUA: satp_alua_issueCommandOnPath:661: Path "vmhba4:C0:T0:L0" (PERM LOSS) command 0xa3 failed with status Device is permanently unavailable. H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x25 0x0.
2011-08-09T10:43:26.857Z cpu2:853571)WARNING: vmw_psp_rr: psp_rrSelectPathToActivate:972:Could not select path for device "naa.60a98000572d54724a34642d71325763".
2011-08-09T10:43:26.857Z cpu2:853571)WARNING: ScsiDevice: 1223: Device :naa.60a98000572d54724a34642d71325763 has been removed or is permanently inaccessible.
2011-08-09T10:43:26.857Z cpu3:2132)ScsiDeviceIO: 2288: Cmd(0x4124403c1fc0) 0x9e, CmdSN 0xec86 to dev "naa.60a98000572d54724a34642d71325763" failed H:0x8 D:0x0 P:0x0
2011-08-09T10:43:26.858Z cpu3:2132)WARNING: NMP: nmp_DeviceStartLoop:721:NMP Device "naa.60a98000572d54724a34642d71325763" is blocked. Not starting I/O from device.
2011-08-09T10:43:26.858Z cpu2:2127)ScsiDeviceIO: 2316: Cmd(0x4124403c1fc0) 0x25, CmdSN 0xecab to dev "naa.60a98000572d54724a34642d71325763" failed H:0x1 D:0x0 P:0x0 Possible sense data: 0x5 0x25 0x0.
2011-08-09T10:43:26.858Z cpu2:854568)WARNING: ScsiDeviceIO: 7330: READ CAPACITY on device "naa.60a98000572d54724a34642d71325763" from Plugin "NMP" failed. I/O error
2011-08-09T10:43:26.858Z cpu2:854568)ScsiDevice: 1238: Permanently inaccessible device :naa.60a98000572d54724a34642d71325763 has no more open connections. It is now safe to unmount datastores (if any) and delete the device.
2011-08-09T10:43:26.859Z cpu3:854577)WARNING: NMP: nmpDeviceAttemptFailover:562:Retry world restore device "naa.60a98000572d54724a34642d71325763" - no more commands to retry
Ключевое слово здесь - permanently.
Становится понятно, что в случае, когда устройство хранения (LUN) реально сломалось или удалено сознательно, лучше всего избежать ситуации APD и попасть в статус PDL. Сделать это удается хост-серверу ESXi не всегда - по прежнему в vSphere 5.0 Update 1 это обрабатывается в ограниченном количестве случаев, но в vSphere 5.1 обещают существенно доработать этот механизм.
Также есть Advanced Settings на хосте ESXi, которые позволяют управлять дальнейшей судьбой машины, которая оказалась жертвой ситуации PDL. В частности есть 2 следующие расширенные настройки (начиная с vSphere 5.0 Update 1) - первая в категории "Disk", а вторая в расширенных настройках кластера HA:
disk.terminateVMonPDLDefault - если эта настройка включена (True), то в ситуации PDL для устройства, где находится ВМ, эта машина будет выключена. Настройка задается на уровне хоста ESXi и требует его перезагрузки для ее применения.
das.maskCleanShutdownEnabled - это настройка, будучи включенной (True), позволяет механизму VMware HA приступить к восстановлению виртуальной машины. Соответственно, если она выключена, то HA проигнорирует выключение виртуальной машины в случае ее "убийства" при включенной первой настройке.
Рекомендуется, чтобы обе эти настройки были включены.
Все описанные выше механизмы могут очень пригодиться при построении и обработке сбоев в "растянутых кластерах" VMware HA, построенных между географически разнесенными датацентрами. Об этом всем детально написано в документе "VMware vSphere Metro Storage Cluster Case Study".
Таги: VMware, vSphere, Storage, Performance, Troubleshooting, HA, ESXi
Компания StarWind, выпускающая продукт номер 1 для создания отказоустойчивых iSCSI-хранилищ серверов VMware vSphere и Microsoft Hyper-V, опять объявила о бесплатной раздаче NFS-лицензий на StarWind iSCSI SAN и StarWind Native SAN for Hyper-V для определенных групп ИТ-профессионалов. В их число входят:
Традиционно, бесплатные лицензии раздаются только для непроизводственного использования, т.е. только для целей тестирования, обучения, демонстраций и т.п. Ну и напомним, что если вы не принадлежите к данным группам ИТ-профессионалов, вы всегда можете скачать бесплатную версию StarWind iSCSI SAN Free, где есть следующие возможности:
Мы уже писали о новых возможностях VMware View 5.1 и, в частности, о технологии Storage Accelerator, которая использует кэш CBRC на чтение на стороне хоста VMware ESXi, чтобы быстрее отдавать блоки виртуальной машине напрямую из памяти, не обращаясь к хранилищу.
Как понятно из названия (Content Based Read Cache), технология Storage Accelerator позволяет оптимизировать ввод-вывод именно тогда, когда в среде виртуальных ПК у нас много операций чтения, которые происходят для множества связанных клонов, развертываемых из реплики View Compser. Таких показательных ситуаций две: Boot Storm (когда пользователи приходят на работу и одновременно включают свои ПК для доступа к своим виртуальным машинам) и Antivirus Storm (когда антивирус начинает шерстить файлы в гостевой ОС).
Интересные картинки по тестированию данной технологии обнаружились в одном из тестов Login VSI, которая проверила, как это работает на хосте со 143-мя связанными клонами виртуальных ПК для размера кэша CBRC размером в 2 ГБ. Работает это замечательно:
Как мы видим, к сотой минуте нагрузка улеглась и операции чтения стали уже не такими однородными. Для постоянных (persistent) дисков (т.е. тех, которые не развертываются из единого базового образа) технология CBRC тоже дает свои плоды:
Ну и здорово помогает нам View Storage Accelerator при антивирусном шторме, когда антивирусники большого количества виртуальных машин одновременно набрасываются на файлы гостевых ОС:
Ну и под конец напомним, что в качестве антивирусных решений в VDI-средах для оптимизации нагрузки нужно использовать решения с поддержкой VMsafe.
Мы уже писали об облачной платформе Amazon Web Services (AWS), куда включен продукт Amazon Elastic Compute Cloud (EC2) - один из самых известных сервисов IaaS по аренде ресурсов для виртуальных машин. Недавно компания Amazon объявила, что теперь есть не только возможность импорта виртуальных машин на платформах вендоров VMware, Citrix и Microsoft, но и обратный их экспорт в частное облако клиента в соответствующих форматах. Несмотря на то, что технически сделать это весьма просто, компания затягивала с этой возможностью.
Экспорт инстанса делается средствами командной строки с помощью задачи ec2-create-instance-export-task. Например, в формат VMware можно экспортировать следующим образом:
Для экспорта потребуется ID инстанса, имя хранилища (S3 Bucket) и тип выходного образа (vmware, citrix или microsoft).
Мониторинг процесса экспорта выполняется командой ec2-describe-export-tasks, а отмена экспорта - ec2-cancel-export-task. Полный синтаксис операций экспорта экземпляров EC2 в виртуальные машины частного облака можно изучить по этой ссылке.
Какие требования предъявляет дедупликация StarWind к аппаратному обеспечению:
Процессор. Минимально на сервере StarWind вам потребуются процессоры Intel Xeon Processor E5620 (или более поздние), либо их аналог по производительности от AMD. Рекомендуются процессоры Intel Xeon X5650 для получения максимальной производительности. При этом лучше иметь больше ядер с меньшей частотой, чем меньше ядер с большей частотой (раки по 3 рубля выгоднее) - это дает большую производительность для StarWind.
Память. Минимальное требование к опреативной памяти сервера StarWind iSCSI SAN - 4 ГБ. При этом нужно учитывать, что нужно закладывать сверх этого память на 2 вещи: дедупликацию и кэширование. Размер памяти, выделяемой для кэширования, выставляется в настройках при создании устройства StarWind, а вот размер памяти, необходимый для дедупликации понятен из следующей таблицы:
Больший размер блока дедупликации дает экономию памяти и процессорных ресурсов, но ухудшает показатели эффективности дедупликации, а на малых размерах блока дедупликации вам понадобятся существенные ресурсы сервера хранилищ StarWind. Ну и от размера блока зависит максимально поддерживаемый объем дедуплицированного диска (от 2 ТБ для 512 байт до 1024 ТБ для 256 КБ).
С точки зрения программного обеспечения, StarWind iSCSI SAN поддерживает любую серверную ОС Microsoft от Windows Server 2003 до Windows 2008 R2, но последняя является рекомендуемой платформой.
В интерфейсе StarWind дедуплицированное устройство создается с помощью мастера:
Далее просто выбираем размер блока дедупликации:
При настройке задачи резервного копирования в Veeam Backup and Replication на дедуплицированное хранилище StarWind не забудьте отключить встроенную дедупликацию от Veeam и компрессию, в соответствии с рекомендациями вендоров:
Кстати, вот один из тестов, показывающих эффективность дедупликации от StarWind для бэкапов Veeam (слева - архив с резервной копией, справа - файл дедуплицированного устройства StarWind):
Мы уже недавно писали о метриках производительности хранилищ в среде VMware vSphere, которые можно получить с помощью команды esxtop. Сегодня мы продолжим развивать эту тему и поговорим об общей производительности дисковых устройств и сайзинге нагрузок виртуальных машин по хранилищам в виртуальной среде.
Как говорит нам вторая статья блога VMware о хранилищах, есть несколько причин, по которым может падать производительность подсистемы ввода-вывода виртуальных машин:
Неправильный сайзинг хранилищ для задач ВМ, вследствие чего хранилища не выдерживают такого количества операций, и все начинает тормозить. Это самый частый случай.
Перегрузка очереди ввода-вывода со стороны хост-сервера.
Достижение предела полосы пропускания между хостом и хранилищем.
Высокая загрузка CPU хост-сервера.
Проблемы с драйверами хранилищ на уровне гостевой ОС.
Некорректно настроенные приложения.
Из всего этого набора причин самой актуальной оказывается, как правило, первая. Это происходит вследствие того, что администраторы очень часто делают сайзинг хранилищ для задач в ВМ, учитывая их требования только к занимаемому пространству, но не учитывая реальных требований систем к вводу выводу. Это верно в Enterprise-среде, когда у вас есть хранилища вроде HDS VSP с практически "несъедаемой" производительностью, но неверно для Low и Midrange массивов в небольших организациях.
Поэтому профилирование нагрузки по хранилищам - одна из основных задач администраторов VMware vSphere. Здесь VMware предлагает описывать модель нагрузки прикладной системы следующими параметрами:
Размер запроса ввода-вывода (I/O Size)
Процент обращений на чтение (Read)
Процент случайных обращений (Random)
Таким образом профиль приложения для "типичной" нагрузки может выглядеть наподобие:
8KB I/O size, 80% Random, 80% Read
Само собой, для каждого приложения типа Exchange или СУБД может быть свой профиль нагрузки, отличающийся от типичного. Размер запроса ввода-вывода (I/O Size) также зависит от специфики приложения, и о том, как регулировать его максимальное значение на уровне гипервизора ESXi, рассказано в KB 1008205. Нужно просто в Advanced Settings выставить значение Disk.DiskMaxIOSize (значение в килобайтах). Некоторые массивы испытывают проблемы с производительностью, когда размер запроса ввода-вывода очень велик, поэтому здесь нужно обратиться к документации производителя массива. Если с помощью указанной настройки ограничить размер запроса ввода-вывода, то они будут разбиваться на маленькие подзапросы, что может привести к увеличению производительности подсистемы ввода-вывода на некоторых системах хранения. По умолчанию установлено максимальное значение в 32 МБ, что является достаточно большим (некоторые массивы начинают испытывать проблемы при запросах более 128 KB, 256 KB или 512KB, в зависимости от модели и конфигурации).
Однако вернемся к профилированию нагрузок по хранилищам в VMware vSphere. В одной из презентаций VMware есть замечательная картинка, отражающая численные характеристики производительности дисковых устройств в пересчете на шпиндель в зависимости от типа их организации в RAID-массивы:
Параметры в верхней части приведены для операций 100%-й последовательной записи для дисков на 15К оборотов. А в нижней части приведены параметры производительности для описанной выше "типичной" нагрузки, включая среднюю скорость чтения-записи, число операций ввода-вывода в секунду (IOPS) и среднюю задержку. Хорошая напоминалка, между прочим.
Теперь как анализировать нагрузку по вводу выводу. Для этого у VMware на сайте проекта VMware Labs есть специальная утилита I/O Analyzer, про которую мы уже писали вот тут. Она может многое из того, что потребуется для профилирования нагрузок по хранилищам.
Ну а дальше стандартные процедуры - балансировка нагрузки по путям, сторадж-процессорам (SP) и дисковым устройствам. Сигналом к изысканиям должен послужить счетчик Device Latency (DAVG) в esxtop, если его значение превышает 20-30 мс для виртуальной машины.
Мы уже писали об основных приемах по решению проблем на хостах VMware ESX / ESXi с помощью утилиты esxtop, позволяющей отслеживать все аспекты производительности серверов и виртуальных машин. Через интерфейс RCLI можно удаленно получать эти же данные с помощью команды resxtop.
Сегодня мы приведем простое объяснение иерархии счетчиков esxtop, касающихся хранилищ серверов VMware vSphere. Для того, чтобы взглянуть на основные счетчики esxtop для хранилищ, нужно запустить утилиту и нажать кнопку <d> для перехода в режим отслеживания показателей конкретных виртуальных машин (кликабельно). Данные значения будут представлены в миллисекундах (ms):
Если мы посмотрим на колонки, которые выделены красным прямоугольником, то в виде иерархии их структуру можно представить следующим образом:
Распишем их назначение:
GAVG (Guest Average Latency) - общая задержка при выполнении SCSI-команд от гостевой ОС до хранилища сквозь все уровни работы машины с блоками данных. Это, само собой, самое большое значение, равное KAVG+DAVG.
KAVG (Kernel Average Latency) - это задержка, возникающая в стеке vSphere для работы с хранилищами (гипервизор, модули для работы SCSI). Это обычно небольшое значение, т.к. ESXi имеет множество оптимизаций в этих компонентах для скорейшего прохождения команд ввода-вывода сквозь них.
QAVG (Queue Average latency) - время, проведенное SCSI-командой в очереди на уровне стека работы с хранилищами, до передачи этой команды HBA-адаптеру.
DAVG (Device Average Latency) - задержка прохождения команд от HBA адаптера до физических блоков данных на дисковых устройствах.
В блоге VMware, где разобраны эти показатели, приведены параметры для типичной нагрузки по вводу-выводу (8k I/O size, 80% Random, 80% Read). Для такой нагрузки показатель Latency (GAVG) 20-30 миллисекунд и более может свидетельствовать о наличии проблем с производительностью подсистемы хранения на каком-то из подуровней.
Как мы уже отметили, показатель KAVG, в идеале, должен быть равен 0 или исчисляться сотыми долями миллисекунды. Если он стабильно находится в пределах 2-3 мс или больше - тут уже можно подозревать проблемы. В этом случае нужно проверить значение столбца QUED для ВМ - если оно достигло 1 (очередь использована), то, возможно, выставлена слишком маленькая величина очереди на HBA-адаптере, и необходимо ее увеличить.
Для просмотра очереди на HBA-адаптере нужно переключиться в представление HBA кнопкой <u>:
Ну и если у вас наблюдается большое значение DAVG, то дело, скорее всего, не в хосте ESX, а в SAN-фабрике или дисковом массиве, на уровне которых возникают большие задержки.
Во-первых, StarWind Global Deduplication работает на уровне дисковых устройств (LUN), а не на уровне VMDK-дисков (как Veeam), что должно положительно сказаться на эффективности дедупликации. По оценкам некоторых пользователей, тестировавших решение, эффективность StarWind доходит до +50% по сравнению с встроенной дедупликацией Veeam.
Во-вторых, на сервере StarWind вам понадобится некоторое количество дополнительной оперативной памяти для работы механизма дедупликации. На данный момент сайзить необходимо следующим образом: 3,5 ГБ памяти на 1 ТБ дедуплицируемого хранилища. В следующих версиях StarWind этот показатель будет близок к 2 ГБ на ТБ.
В-третьих, для Veeam придется отключить компрессию для лучшего эффекта дедупликации, но поддержка этого механизма в StarWind будет добавлена в ближайших версиях. Также в следующей версии будет добавлена функция увеличения/уменьшения размеров таких устройств и дедпуликация HA-устройств. Об этом всем мы напишем дополнительно.
Не секрет, что абсолютное большинство пользователей VMware vSphere, думающих о защите данных виртуальной среды, использует средство номер 1 для резервного копирования виртуальных машин Veeam Backup and Replication 6. Компании Veeam Software и StarWind Software недавно объявили о запуске совместной компании, в рамках которой всем пользователям Veeam Backup and Replication абсолютно бесплатно предоставляется средство дедупликации хранилищ резервных копий StarWind Global Deduplication, которое позволяет сократить требования к объему хранения до 90%.
Пример эффективности совместного использования Veeam Backup and Replication и StarWind Global Deduplication показан на картинке ниже:
Решение StarWind Global Deduplication предосталяется бесплатно всем пользователям Veeam, сертифицировано со стороны последней, а также включает в себя техническую поддержку в режиме 24/7.
Мы уже не раз писали о типах устройств в продукте StarWind iSCSI Target, который предназначен для создания отказоустойчивых iSCSI-хранилищ для серверов VMware vSphere и Microsoft Hyper-V, однако с тех времен много что изменилось: StarWind стал поддерживать дедуплицированные хранилища и новые типы устройств, которые могут пригодиться при организации различных типов хранилищ и о которых мы расскажем ниже...
Таги: StarWind, iSCSI, SAN, Enteprirse, HA, Storage, VMware, vSphere
Вы уже, наверняка, читали про новые возможности VMware View 5.1, а на днях обновился калькулятор VDI Flash Calculator до версии 2.8, предназначенный для расчета вычислительных мощностей и хранилищ, поддерживающий новые функции платформы виртуализации настольных ПК.
Среди новых возможностей калькулятора VDI:
Поддержка VMware View 5.1
Поддержка функции VMware View CBRC для системного диска (Content Based Read Cache) - предполагается уменьшение интенсивности ввода-вывода на чтение на 65%
Поддержка связанных клонов на томах NFS для кластеров vSphere, состоящих из более чем 8-ми хостов
Поддержка платформ с высокой плотностью размещения виртуальных ПК
Поддержка разрешения экрана 2560×1600
Небольшие изменения в интерфейсе
Ну и небольшое обзорное видео работы с калькулятором:
Мы уже некоторое время назад писали про различные особенности томов VMFS, где вскользь касалисьпроблемы блокировок в этой кластерной файловой системе. Как известно, в платформе VMware vSphere 5 реализована файловая система VMFS 5, которая от версии к версии приобретает новые возможности.
При этом в VMFS есть несколько видов блокировок, которые мы рассмотрим ниже. Блокировки на томах VMFS можно условно разделить на 2 типа:
Блокировки файлов виртуальных машин
Блокировки тома
Блокировки файлов виртуальных машин
Эти блокировки необходимы для того, чтобы файлами виртуальной машины мог в эксклюзивном режиме пользоваться только один хост VMware ESXi, который их исполняет, а остальные хосты могли запускать их только тогда, когда этот хост вышел из строя. Назвается этот механизм Distributed Lock Handling.
Блокировки важны, во-первых, чтобы одну виртуальную машину нельзя было запустить одновременно с двух хостов, а, во-вторых, для их обработки механизмом VMware HA при отказе хоста. Для этого на томе VMFS существует так называемый Heartbeat-регион, который хранит в себе информацию о полученных хостами блокировок для файлов виртуальных машин.
Обработка лока на файлы ВМ происходит следующим образом:
Хосты VMware ESXi монтируют к себе том VMFS.
Хосты помещают свои ID в специальный heartbeat-регион на томе VMFS.
ESXi-хост А создает VMFS lock в heartbeat-регионе тома для виртуального диска VMDK, о чем делается соответствующая запись для соответствующего ID ESXi.
Временная метка лока (timestamp) обновляется этим хостом каждые 3 секунды.
Если какой-нибудь другой хост ESXi хочет обратиться к VMDK-диску, он проверяет наличие блокировки для него в heartbeat-регионе. Если в течение 15 секунд (~5 проверок) ESXi-хост А не обновил timestamp - хосты считают, что хост А более недоступен и блокировка считается неактуальной. Если же блокировка еще актуальна - другие хосты снимать ее не будут.
Если произошел сбой ESXi-хоста А, механизм VMware HA решает, какой хост будет восстанавливать данную виртуальную машину, и выбирает хост Б.
Далее все остальные хосты ESXi виртуальной инфраструктуры ждут, пока хост Б снимет старую и поставит свою новую блокировку, а также накатит журнал VMFS.
Данный тип блокировок почти не влияет на производительность хранилища, так как происходят они в нормально функционирующей виртуальной среде достаточно редко. Однако сам процесс создания блокировки на файл виртуальной машины вызывает второй тип блокировки - лок тома VMFS.
Блокировки на уровне тома VMFS
Этот тип блокировок необходим для того, чтобы хост-серверы ESXi имели возможность вносить изменения в метаданные тома VMFS, обновление которых наступает в следующих случаях:
Создание, расширение (например, "тонкий" диск) или блокировка файла виртуальной машины
Изменение атрибутов файла на томе VMFS
Включение и выключение виртуальной машины
Создание, расширение или удаление тома VMFS
Создание шаблона виртуальной машины
Развертывание ВМ из шаблона
Миграция виртуальной машины средствами vMotion
Для реализации блокировок на уровне тома есть также 2 механизма:
Механизм SCSI reservations - когда хост блокирует LUN, резервируя его для себя целиком, для создания себе эксклюзивной возможности внесения изменений в метаданные тома.
Механизм "Hardware Assisted Locking", который блокирует только определенные блоки на устройстве (на уровне секторов устройства).
Наглядно механизм блокировок средствами SCSI reservations можно представить так:
Эта картинка может ввести в заблуждение представленной последовательностью операций. На самом деле, все происходит не совсем так. Том, залоченный ESXi-хостом А, оказывается недоступным другим хостам только на период создания SCSI reservation. После того, как этот reservation создан и лок получен, происходит обновление метаданных тома (более длительная операция по сравнению с самим резервированием) - но в это время SCSI reservation уже очищен, так как лок хостом А уже получен. Поэтому в процессе самого обновления метаданных хостом А все остальные хосты продолжают операции ввода-вывода, не связанные с блокировками.
Надо сказать, что компания VMware с выпуском каждой новой версии платформы vSphere вносит улучшения в механизм блокировки, о чем мы уже писали тут. Например, функция Optimistic Locking, появившаяся еще для ESX 3.5, позволяет собирать блокировки в пачки, максимально откладывая их применение, а потом создавать один SCSI reservation для целого набора локов, чтобы внести измененения в метаданные тома VMFS.
С появлением версии файловой системы VMFS 3.46 в vSphere 4.1 появилась поддержка функций VAAI, реализуемых производителями дисковых массивов, так называемый Hardware Assisted Locking. В частности, один из алгоритмов VAAI, отвечающий за блокировки, называется VAAI ATS (Atomic Test & Set). Он заменяет собой традиционный механизм SCSI reservations, позволяя блокировать только те блоки метаданных на уровне секторов устройства, изменение которых в эксклюзивном режиме требуется хостом. Действует он для всех перечисленных выше операций (лок на файлы ВМ, vMotion и т.п.).
Если дисковый массив поддерживает ATS, то традиционная последовательность SCSI-комманд RESERVE, READ, WRITE, RELEASE заменяется на SCSI-запрос read-modify-write для нужных блокировке блоков области метаданных, что не вызывает "замораживания" LUN для остальных хостов. Но одновременно метаданные тома VMFS, естественно, может обновлять только один хост. Все это лучшим образом влияет на производительность операций ввода-вывода и уменьшает количество конфликтов SCSI reservations, возникающих в традиционной модели.
По умолчанию VMFS 5 использует модель блокировок ATS для устройств, которые поддерживают этот механизм VAAI. Но бывает такое, что по какой-либо причине, устройство перестало поддерживать VAAI (например, вы откатили обновление прошивки). В этом случае обработку блокировок средствами ATS для устройства нужно отменить. Делается это с помощью утилиты vmkfstools:
vmkfstools --configATSOnly 0 device
где device - это пусть к устройству VMFS вроде следующего:
Сотрудники компании VMware не так давно на корпоративном блоге публиковали заметки о сравнении протоколов FC, iSCSI, NFS и FCoE, которые используются в VMware vSphere для работы с хранилищами. В итоге эта инициатива переросла в документ "Storage Protocol Comparison", который представляет собой сравнительную таблицу по различным категориям, где в четырех столбиках приведены преимущества и особенности того или иного протокола:
Полезная штука со многими познавательными моментами.
Одним из ключевых нововведений VMware vSphere 5, безусловно, стала технология выравнивания нагрузки на хранилища VMware vSphere Storage DRS (SDRS), которая позволяет оптимизировать нагрузку виртуальных машин на дисковые устройства без прерывания работы ВМ средствами технологии Storage vMotion, а также учитывать характеристики хранилищ при их первоначальном размещении.
Основными функциями Storage DRS являются:
Балансировка виртуальных машин между хранилищами по вводу-выводу (I/O)
Балансировка виртуальных машин между хранилищами по их заполненности
Интеллектуальное первичное размещение виртуальных машин на Datastore в целях равномерного распределения пространства
Учет правил существования виртуальных дисков и виртуальных машин на хранилищах (affinity и anti-affinity rules)
Ключевыми понятими Storage DRS и функции Profile Driven Storage являются:
Datastore Cluster - кластер виртуальных хранилищ (томов VMFS или NFS-хранилищ), являющийся логической сущностью в пределах которой происходит балансировка. Эта сущность в чем-то похожа на обычный DRS-кластер, который составляется из хост-серверов ESXi.
Storage Profile - профиль хранилища, используемый механизмом Profile Driven Storage, который создается, как правило, для различных групп хранилищ (Tier), где эти группы содержат устройства с похожими характеристиками производительности. Необходимы эти профили для того, чтобы виртуальные машины с различным уровнем обслуживания по вводу-выводу (или их отдельные диски) всегда оказывались на хранилищах с требуемыми характеристиками производительности.
При создании Datastore Cluster администратор указывает, какие хранилища будут в него входить (максимально - 32 штуки в одном кластере):
Как и VMware DRS, Storage DRS может работать как в ручном, так и в автоматическом режиме. То есть Storage DRS может генерировать рекомендации и автоматически применять их, а может оставить их применение на усмотрение пользователя, что зависит от настройки Automation Level.
С точки зрения балансировки по вводу-выводу Storage DRS учитывает параметр I/O Latency, то есть round trip-время прохождения SCSI-команд от виртуальных машин к хранилищу. Вторым значимым параметром является заполненность Datastore (Utilized Space):
Параметр I/O Latency, который вы планируете задавать, зависит от типа дисков, которые вы используете в кластере хранилищ, и инфраструктуры хранения в целом. Однако есть некоторые пороговые значения по Latency, на которые можно ориентироваться:
SSD-диски: 10-15 миллисекунд
Диски Fibre Channel и SAS: 20-40 миллисекунд
SATA-диски: 30-50 миллисекунд
По умолчанию рекомендации по I/O Latency для виртуальных машин обновляются каждые 8 часов с учетом истории нагрузки на хранилища. Также как и DRS, Storage DRS имеет степень агрессивности: если ставите агрессивный уровень - миграции будут чаще, консервативный - реже. Первой галкой "Enable I/O metric for SDRS recommendations" можно отключить генерацию и выполнение рекомендаций, которые основаны на I/O Latency, и оставить только балансировку по заполненности хранилищ.
То есть, проще говоря, SDRS может переместить в горячем режиме диск или всю виртуальную машину при наличии большого I/O Latency или высокой степени заполненности хранилища на альтернативный Datastore.
Самый простой способ - это балансировка между хранилищами в кластере на базе их заполненности, чтобы не ломать голову с производительностью, когда она находится на приемлемом уровне.
Администратор может просматривать и применять предлагаемые рекомендации Storage DRS из специального окна:
Когда администратор нажмет кнопку "Apply Recommendations" виртуальные машины за счет Storage vMotion поедут на другие хранилища кластера, в соответствии с определенным для нее профилем (об этом ниже).
Аналогичным образом работает и первичное размещение виртуальной машины при ее создании. Администратор определяет Datastore Cluster, в который ее поместить, а Storage DRS сама решает, на какой именно Datastore в кластере ее поместить (основываясь также на их Latency и заполненности).
При этом, при первичном размещении может случиться ситуация, когда машину поместить некуда, но возможно подвигать уже находящиеся на хранилищах машины между ними, что освободит место для новой машины (об этом подробнее тут):
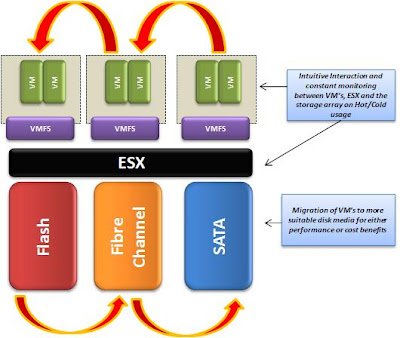
Как видно из картинки с выбором кластера хранилищ для новой ВМ, кроме Datastore Cluster, администратор первоначально выбирает профиль хранилищ (Storage Profile), который определяет, по сути, уровень производительности виртуальной машины. Это условное деление хранилищ, которое администратор задает для хранилищ, обладающих разными характеристиками производительности. Например, хранилища на SSD-дисках можно объединить в профиль "Gold", Fibre Channel диски - в профиль "Silver", а остальные хранилища - в профиль "Bronze". Таким образом вы реализуете концепцию ярусного хранения данных виртуальных машин:
Выбирая Storage Profile, администратор будет всегда уверен, что виртуальная машина попадет на тот Datastore в рамках выбранного кластера хранилищ, который создан поверх дисковых устройств с требуемой производительностью. Профиль хранилищ создается в отельном интерфейсе VM Storage Profiles, где выбираются хранилища, предоставляющие определенный набор характеристик (уровень RAID, тип и т.п.), которые платформа vSphere получает через механизм VASA (VMware vStorage APIs for Storage Awareness):
Ну а дальше при создании ВМ администратор определяет уровень обслуживания и характеристики хранилища (Storage Profile), а также кластер хранилища, датасторы которого удовлетворяют требованиям профиля (они отображаются как Compatible) или не удовлетворяют им (Incompatible). Концепция, я думаю, понятна.
Регулируются профили хранилищ для виртуальной машины в ее настройках, на вкладке "Profiles", где можно их настраивать на уровне отдельных дисков:
На вкладке "Summary" для виртуальной машины вы можете увидеть ее текущий профиль и соответствует ли в данный момент она его требованиям:
Также можно из оснастки управления профилями посмотреть, все ли виртуальные машины находятся на тех хранилищах, профиль которых совпадает с их профилем:
Далее - правила размещения виртуальных машин и их дисков. Определяются они в рамках кластера хранилищ. Есть 3 типа таких правил:
Все виртуальные диски машины держать на одном хранилище (Intra-VM affinity) - установлено по умолчанию.
Держать виртуальные диски обязательно на разных хранилищах (VMDK anti-affinity) - например, чтобы отделить логи БД и диски данных. При этом такие диски можно сопоставить с различными профилями хранилищ (логи - на Bronze, данны - на Gold).
Держать виртуальные машины на разных хранилищах (VM anti-affinity). Подойдет, например, для разнесения основной и резервной системы в целях отказоустойчивости.
Естественно, у Storage DRS есть и свои ограничения. Основные из них приведены на картинке ниже:
Основной важный момент - будьте осторожны со всякими фичами дискового массива, не все из которых могут поддерживаться Storage DRS.
И последнее. Технологии VMware DRS и VMware Storage DRS абсолютно и полностью соместимы, их можно использовать совместно.

 RSS
RSS